

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Hacking RomHacking in Tales of Destiny 2
- Thread starter SkyBladeCloud
- Start date
- Views 45,118
- Replies 60
- Likes 16



I tried this and could not do it.
Red: offset of first file?
Orange: I noticed that there is this much padding at the end of the first file. The first file appears to end at 0x48BB4 and the second file starts at 0x49000, there is exactly 0x44C between those. Does not appear to be the offset of a file.
Green: Does not appear to be the offset of a file
Blue: Appears to be the offset of a file
It's stated in the first post there's 21 bits for address data and 11 for flags. That does not make sense unless special tricks are being used. You need 30 bits to address every byte in a 600MB file like this.

View attachment 104329
Red: offset of first file?
Nope, this may sound confusing, but the pointer table starts at the 0x44c, which references the very first file in the package (the font).
It's stated in the first post there's 21 bits for address data and 11 for flags. That does not make sense unless special tricks are being used. You need 30 bits to address every byte in a 600MB file like this.
Well, yeah, the post was more in the line of proving that the project was indeed possible, as well as showing how much research was already put into it. It was not as detailed as an actual romhacking guide would be, but since I have good memory I think I can still answer your query, even though it's been years since I last had a look at this game...
You see, 21 bits are enough to reference any file in the package. That's because they represent not a byte offset, but a sector in the disc. The ISO9660 standard uses 0x0800 bytes sectors. The way to work with them actually depends of the way you think it though:
-if you shift 11 bits from data, you'll get the file sector, so you can get the byte offset multiplying that value by 0x0800.
-Since these 21 bits take the most significant part of the data, you can apply a 0xFFFFF800 mask to it, to directly get the byte offset to the file.
Now, the remaining 11 bits are not binary flags, they mostly specify the "loading type" of the file:
-If it's 0, the file is read as a "stream", meaning that the game won't fully load it into memory, but read it chunk by chunk until consuming the whole stream. This is used for multimedia resources, and IIRC some compressed packages too, where the game decompress one file at a time instead of reading the whole package before starting the decompression.
-If it's different than 0, then the file is read as a "register", meaning that the game will fully load it to memory (and deserialize it using its data structures). In this case, the 11 bits specify the remaining size untill the next file. If you notice, the 2Kb disk sector size is exactly 2^11 bytes, so everything makes perfect sense. You can calculate the file size like:
Code:
unsigned int fileSize = (nextSector - currentSector) * 0x0800 - remainder;Or, if you masked the data to directly get the byte offset, you can avoid multiplying by 0x0800, but as far as I remember, the game code uses the sector approach.
For example, to extract the font we would look at the following data:
-First file -> Sector 0, remainer 0x044c
-Second file -> Sector 92
-Offset = 0 * 0x0800 = 0
-Size = (92 - 0) * 0x0800 - 0x044c = 48BB4
And that should cover extracting the FBP.
Regards:
~Sky
Last edited by SkyBladeCloud,
I'll post in that other thread when I have a tool that's working good.
That makes sense now.
My next question was about LZSS and LZSS + RLE. My understanding was these are not algorithms but ideas that different compression tools use. I am actually familiar with both ideas so I don't need an explanation. Is there a tool that will do these, or do I need to look at game routines and reverse-engineer them? I like working in python, and the good people at python.org have had a zlib module for quite awhile now, so that problem is solved.
That makes sense now.
My next question was about LZSS and LZSS + RLE. My understanding was these are not algorithms but ideas that different compression tools use. I am actually familiar with both ideas so I don't need an explanation. Is there a tool that will do these, or do I need to look at game routines and reverse-engineer them? I like working in python, and the good people at python.org have had a zlib module for quite awhile now, so that problem is solved.
Well, if you want an already made tool that does work with files following the LZSS (+ RLE) implementation of this specific game...
Yeah, actually there is such thing:
https://github.com/talestra/talestra/tree/master/compto
You can start with just ZLib, though, while the PSP code does support LZSS/RLE decompression, IIRC it includes no LZSS/RLE compressed files by default, so you should be able to fully decompress the PSP game using ZLib alone... Then you can use LZSS/RLE in case you want to use the same compressed data in both version of the game xD...
~Sky
EDIT: Since you mentioned the other thread, I take it you'll be helping in the romhacking department of that project. I think that before starting any serious coding, you should make sure you guys are capable of extracting the text from the game script files. This is going to be BY FAAAAAAAR the hardest part of the whole project (at least in terms of hacking). Doing it "the right way"* actually requires disassembling object code from a custom virtual machine / interpreter. It's pretty much like extracting strings from a .pyc file, with the added difficulty that this custom execution environment is totally game-specific and thus undocumented.
I know more than a couple efforts that were cancelled when reaching this part of the project, and they were left with tools for the rest of formats than didn't really had any use since the translation was not possible without the script...
*Of course there are more ways to do things, apart from just the "the right way"")
...
Yeah, actually there is such thing:
https://github.com/talestra/talestra/tree/master/compto
You can start with just ZLib, though, while the PSP code does support LZSS/RLE decompression, IIRC it includes no LZSS/RLE compressed files by default, so you should be able to fully decompress the PSP game using ZLib alone... Then you can use LZSS/RLE in case you want to use the same compressed data in both version of the game xD...
~Sky
EDIT: Since you mentioned the other thread, I take it you'll be helping in the romhacking department of that project. I think that before starting any serious coding, you should make sure you guys are capable of extracting the text from the game script files. This is going to be BY FAAAAAAAR the hardest part of the whole project (at least in terms of hacking). Doing it "the right way"* actually requires disassembling object code from a custom virtual machine / interpreter. It's pretty much like extracting strings from a .pyc file, with the added difficulty that this custom execution environment is totally game-specific and thus undocumented.
I know more than a couple efforts that were cancelled when reaching this part of the project, and they were left with tools for the rest of formats than didn't really had any use since the translation was not possible without the script...
*Of course there are more ways to do things, apart from just the "the right way"
...
Last edited by SkyBladeCloud,
I'm not really asking for advice, just trying to show the progress.
I think this is the routine decoding the double-byte characters. It gives a return value as an index into that letters table I'll refer to as "0001.bin" (second file in the big archive). So we can use that to decode.
To clarify, the return value is the letter position. You have to double it to get the offset. We're using python so we don't have to worry about that

I implemented it fully in python (it's not too long) and it gives the same answers the game does. https://pastebin.com/fCVPLUP4
Then I thought about it some. It looks like it could be:
p = parameter
t1 = ((p >> 8) - 0x99) * 0xBB
t2 = (p & 0xFF) - 2
answer = t1 + t2
But I tried that and it didn't work (for every value, that is), so I'll just go with the longer routine I already wrote.
I still haven't figured out the single-byte characters.
Next, I'll try decoding files using the information you provided. That will help me understand what the single-byte characters look like (?). Like most games in Japanese, it doesn't use single-byte characters too often.
Having trouble decoding. Dealing with edge cases right now. I found:
0x01 is linebreak
0x02 is pagebreak
0x152202C0 is カイル (tried other combinations but nothing, best guess is it gets the name of a party member)
0x07 plus a full-word integer operand gives a character name. 1 = カイル, 2 = Reala, etc...
But the full word operand means splitting strings based on b'\x00' won't work anymore *sob* (looks like 0x01000000)
Note: I am not having trouble decoding letters. That's working fine.
I think this is the routine decoding the double-byte characters. It gives a return value as an index into that letters table I'll refer to as "0001.bin" (second file in the big archive). So we can use that to decode.
To clarify, the return value is the letter position. You have to double it to get the offset. We're using python so we don't have to worry about that
I implemented it fully in python (it's not too long) and it gives the same answers the game does. https://pastebin.com/fCVPLUP4
Then I thought about it some. It looks like it could be:
p = parameter
t1 = ((p >> 8) - 0x99) * 0xBB
t2 = (p & 0xFF) - 2
answer = t1 + t2
But I tried that and it didn't work (for every value, that is), so I'll just go with the longer routine I already wrote.
I still haven't figured out the single-byte characters.
Next, I'll try decoding files using the information you provided. That will help me understand what the single-byte characters look like (?). Like most games in Japanese, it doesn't use single-byte characters too often.
Having trouble decoding. Dealing with edge cases right now. I found:
0x01 is linebreak
0x02 is pagebreak
0x152202C0 is カイル (tried other combinations but nothing, best guess is it gets the name of a party member)
0x07 plus a full-word integer operand gives a character name. 1 = カイル, 2 = Reala, etc...
But the full word operand means splitting strings based on b'\x00' won't work anymore *sob* (looks like 0x01000000)
Note: I am not having trouble decoding letters. That's working fine.
Attachments
Last edited by flame1234,
Here is the tool: https://www.mediafire.com/file/e44c1ksxl7a17z8/ToD2 String Extract v1.7z
Instructions are in the included readme. It will dump all strings in .SCED files to the best of its ability. (Too big for forum attachment because of included binary, 138kB.)
When you are finished, you may want to concatenate .tsv files into a spreadsheet. I wrote a program today that does that too using LibreOffice: https://heroesoflegend.org/forums/viewtopic.php?f=38&t=349
I found 845k characters. But not all of them have to be translated. Mostly because of a large number of repeats. I have no idea how to get a better estimate.
I put a deduplication function in this tool, each of the repeating strings needs to be translated only once.
Please take a look at this sample:
https://docs.google.com/spreadsheets/d/1s1cHvhnX4Z7nctDvD4RTDprxDn68kIqfp4aTRMp51jA/edit#gid=0
Definitely don't start translating yet. I have no confidence in my ability to insert this back. Let me at least put Lorem ipsum in there for you to prove it can be done.
I am not too happy with it because function boundaries are not identified.
What I mean by function boundary: At some point during the first scene it jumps to a different file, then jumps back to the first one.
I tried, but I can't find them. If you look in the sample, 6470 line 34 is the last one before the switch.
Translators will not be able to follow the game flow and that will make their translation worse than it could be.
I was scared that translators wouldn't be able to ID who's talking but it seems that won't be a problem.
More stuff on the strings. I couldn't figure a lot of them. Any ideas?
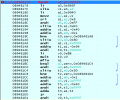
These commands were the main ones: 0x12, 0x14, 0x15, 0x16, 0x17, 0x18. They all seem to have variable length operands ending in 0xBC or 0xC0, so I just assumed that and it seemed to work fine, but I just dumped them as raw bytes since I don't know what they do. I used my usual method (type in the bytes at the first string of the game) but either nothing shows up or, more rarely, it crashes the game, when I do that.
I also couldn't figure out 0x03 or 0x0B, but those seem to take a full-word integer operand.
I was having troubling unpacking the code sections (necessary for insert).
11: 1
24: 1
31: 1, 34: 1
80: 0, 81: 0, 82: 1, 83: 0
90: 1, 91: 1, 93: 1
A0: 2
C0: 0, C2: 0, C5: 0, CD: 0
D0: 0, D5: 0, D7: 0
E0: 1
F0: 0, F1: 2 (not sure), F2: 2 (pointer), F3: 2 (pointer), F8: 2 (pointer)
For pointers I think I can identify which are applicable to the string table by searching for the offsets of the start of strings. Some pointers are applicable to the code table.
And do you have advice for the lowercase letters? I was thinking of modifying the font, if I can find it (the halfwidth font is somewhere else). And then using a translation table to translate strings into halfwidth katakana.
Instructions are in the included readme. It will dump all strings in .SCED files to the best of its ability. (Too big for forum attachment because of included binary, 138kB.)
When you are finished, you may want to concatenate .tsv files into a spreadsheet. I wrote a program today that does that too using LibreOffice: https://heroesoflegend.org/forums/viewtopic.php?f=38&t=349
I found 845k characters. But not all of them have to be translated. Mostly because of a large number of repeats. I have no idea how to get a better estimate.
I put a deduplication function in this tool, each of the repeating strings needs to be translated only once.
Please take a look at this sample:
https://docs.google.com/spreadsheets/d/1s1cHvhnX4Z7nctDvD4RTDprxDn68kIqfp4aTRMp51jA/edit#gid=0
Definitely don't start translating yet. I have no confidence in my ability to insert this back. Let me at least put Lorem ipsum in there for you to prove it can be done.
I am not too happy with it because function boundaries are not identified.
What I mean by function boundary: At some point during the first scene it jumps to a different file, then jumps back to the first one.
I tried, but I can't find them. If you look in the sample, 6470 line 34 is the last one before the switch.
Translators will not be able to follow the game flow and that will make their translation worse than it could be.
I was scared that translators wouldn't be able to ID who's talking but it seems that won't be a problem.
More stuff on the strings. I couldn't figure a lot of them. Any ideas?
These commands were the main ones: 0x12, 0x14, 0x15, 0x16, 0x17, 0x18. They all seem to have variable length operands ending in 0xBC or 0xC0, so I just assumed that and it seemed to work fine, but I just dumped them as raw bytes since I don't know what they do. I used my usual method (type in the bytes at the first string of the game) but either nothing shows up or, more rarely, it crashes the game, when I do that.
I also couldn't figure out 0x03 or 0x0B, but those seem to take a full-word integer operand.
I was having troubling unpacking the code sections (necessary for insert).
Any tips on doing this? There's more than just a few operands, there are a lot. (Sizes don't include the operand byte)***Possible answer B (clean one): We disassemble the SCED interpreter's native MIPS code and write down all possible opcode and operand sizes.
11: 1
24: 1
31: 1, 34: 1
80: 0, 81: 0, 82: 1, 83: 0
90: 1, 91: 1, 93: 1
A0: 2
C0: 0, C2: 0, C5: 0, CD: 0
D0: 0, D5: 0, D7: 0
E0: 1
F0: 0, F1: 2 (not sure), F2: 2 (pointer), F3: 2 (pointer), F8: 2 (pointer)
For pointers I think I can identify which are applicable to the string table by searching for the offsets of the start of strings. Some pointers are applicable to the code table.
And do you have advice for the lowercase letters? I was thinking of modifying the font, if I can find it (the halfwidth font is somewhere else). And then using a translation table to translate strings into halfwidth katakana.
Last edited by flame1234,
Sorry I found this a bit too late. I am the programmer behind the Chinese translation project of this game years ago (along with the Tales of Rebirth Chinese translation project). I think I still have the Java code to unpack (as well as decrypt, if necessary, any compressed segment, and I remember there are 4 types of files, with type 4 using gzip and a simple header) and repack that big file. I am happy to give out the code so you guys can go from there (sorry I am unable to provide any technical support at this point since my life is too busy), and I think the code is pretty much all you need to make the translation with a programmer.
Z
zeropain
Guest
@serige: This might be useful to @jenachu and her team:
https://gbatemp.net/threads/tales-of-destiny-2-english-patch-psp-jp-text-rip-required.487604/
https://gbatemp.net/threads/tales-of-destiny-2-english-patch-psp-jp-text-rip-required.487604/
Last edited by ,
Sorry I found this a bit too late. I am the programmer behind the Chinese translation project of this game years ago (along with the Tales of Rebirth Chinese translation project). I think I still have the Java code to unpack (as well as decrypt, if necessary, any compressed segment, and I remember there are 4 types of files, with type 4 using gzip and a simple header) and repack that big file. I am happy to give out the code so you guys can go from there (sorry I am unable to provide any technical support at this point since my life is too busy), and I think the code is pretty much all you need to make the translation with a programmer.
Post the link so someone can use it when they see this, that is awesome. Thanks.


What does that mean? It will be released early?!Hopefully there will be soon~ gambate minna!!!

What does that mean? It will be released early?!
Good question. Right now I don't even know what the current team/teams are.
Uh great? °~°Good question. Right now I don't even know what the current team/teams are.
Oh thats a shameSo is this dead in the water, can't really tell by the posts if it's even being worked atm.

Similar threads
- Replies
- 0
- Views
- 875
- Replies
- 0
- Views
- 2K
- Replies
- 0
- Views
- 2K
Site & Scene News
New Hot Discussed
-
-
24K views
Wii U and 3DS online services shutting down today, but Pretendo is here to save the day
Today, April 8th, 2024, at 4PM PT, marks the day in which Nintendo permanently ends support for both the 3DS and the Wii U online services, which include co-op play...by ShadowOne333 179 -
19K views
Nintendo Switch firmware update 18.0.1 has been released
A new Nintendo Switch firmware update is here. System software version 18.0.1 has been released. This update offers the typical stability features as all other... -
17K views
The first retro emulator hits Apple's App Store, but you should probably avoid it
With Apple having recently updated their guidelines for the App Store, iOS users have been left to speculate on specific wording and whether retro emulators as we... -
16K views
Delta emulator now available on the App Store for iOS
The time has finally come, and after many, many years (if not decades) of Apple users having to side load emulator apps into their iOS devices through unofficial...by ShadowOne333 96 -
15K views
MisterFPGA has been updated to include an official release for its Nintendo 64 core
The highly popular and accurate FPGA hardware, MisterFGPA, has received today a brand new update with a long-awaited feature, or rather, a new core for hardcore...by ShadowOne333 54 -
12K views
TheFloW releases new PPPwn kernel exploit for PS4, works on firmware 11.00
TheFlow has done it again--a new kernel exploit has been released for PlayStation 4 consoles. This latest exploit is called PPPwn, and works on PlayStation 4 systems... -
12K views
Nintendo takes down Gmod content from Steam's Workshop
Nintendo might just as well be a law firm more than a videogame company at this point in time, since they have yet again issued their now almost trademarked usual...by ShadowOne333 113 -
10K views
A prototype of the original "The Legend of Zelda" for NES has been found and preserved
Another video game prototype has been found and preserved, and this time, it's none other than the game that spawned an entire franchise beloved by many, the very...by ShadowOne333 31 -
9K views
Anbernic reveals specs details of pocket-sized RG28XX retro handheld
Anbernic is back with yet another retro handheld device. The upcoming RG28XX is another console sporting the quad-core H700 chip of the company's recent RG35XX 2024... -
9K views
Nintendo "Indie World" stream announced for April 17th, 2024
Nintendo has recently announced through their social media accounts that a new Indie World stream will be airing tomorrow, scheduled for April 17th, 2024 at 7 a.m. PT...by ShadowOne333 53
-
-
-
179 replies
Wii U and 3DS online services shutting down today, but Pretendo is here to save the day
Today, April 8th, 2024, at 4PM PT, marks the day in which Nintendo permanently ends support for both the 3DS and the Wii U online services, which include co-op play...by ShadowOne333 -
113 replies
Nintendo takes down Gmod content from Steam's Workshop
Nintendo might just as well be a law firm more than a videogame company at this point in time, since they have yet again issued their now almost trademarked usual...by ShadowOne333 -
97 replies
The first retro emulator hits Apple's App Store, but you should probably avoid it
With Apple having recently updated their guidelines for the App Store, iOS users have been left to speculate on specific wording and whether retro emulators as we...by Scarlet -
96 replies
Delta emulator now available on the App Store for iOS
The time has finally come, and after many, many years (if not decades) of Apple users having to side load emulator apps into their iOS devices through unofficial...by ShadowOne333 -
79 replies
Nintendo Switch firmware update 18.0.1 has been released
A new Nintendo Switch firmware update is here. System software version 18.0.1 has been released. This update offers the typical stability features as all other...by Chary -
76 replies
TheFloW releases new PPPwn kernel exploit for PS4, works on firmware 11.00
TheFlow has done it again--a new kernel exploit has been released for PlayStation 4 consoles. This latest exploit is called PPPwn, and works on PlayStation 4 systems...by Chary -
55 replies
Nintendo Switch Online adds two more Nintendo 64 titles to its classic library
Two classic titles join the Nintendo Switch Online Expansion Pack game lineup. Available starting April 24th will be the motorcycle racing game Extreme G and another...by Chary -
54 replies
MisterFPGA has been updated to include an official release for its Nintendo 64 core
The highly popular and accurate FPGA hardware, MisterFGPA, has received today a brand new update with a long-awaited feature, or rather, a new core for hardcore...by ShadowOne333 -
53 replies
Nintendo "Indie World" stream announced for April 17th, 2024
Nintendo has recently announced through their social media accounts that a new Indie World stream will be airing tomorrow, scheduled for April 17th, 2024 at 7 a.m. PT...by ShadowOne333 -
52 replies
The FCC has voted to restore net neutrality, reversing ruling from 2017
In 2017, the United States Federal Communications Commission (FCC) repealed net neutrality. At the time, it was a major controversy between internet service providers...by Chary
-
Popular threads in this forum
General chit-chat