

You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
- Joined
- Nov 15, 2011
- Messages
- 5,210
- Trophies
- 0
- Age
- 40
- Location
- Deep in GBAtemp addiction
- Website
- gbadev.googlecode.com
- XP
- 1,709
- Country

You have specs for them?very disappointing specs though, no match for durango/orbis
Plz do share !!
http://gbatemp.net/threads/hacking-the-wiiu-a-simple-progress-guide.338900/page-19

Thanks to the guys at Chipworks and NeoGAF, The Wii U's GPU, "Latte" (C 10234F5) has has a basic decapping done.
(Basic meaning just a Top-Layer Die photo at an exorbitantly high resolution)
http://www.chipworks.com/blog/technologyblog/2013/02/04/looking-at-the-wii-u-graphics-processor/
Plenty of analysis based on the die photo has been done on the NeoGAF Thread, Check it:
http://www.neogaf.com/forum/showthread.php?t=511628
looking something like this
Wii U
3 x OOE CPU at 1.2 ghz
~300-400 Gflops GPU (???)
2GB T1 SRAM @ 12.8 GB/s (???)
32MB eDRAM @ 140 GB/s (???)
1MB sRAM/eDRAM (???)
Durango
6 x OOE CPU at 1.6 ghz
1.243 Gflops GPU (3 - 4x more than Wii U)
8GB DDR3 RAM @ 68GB/s (4x more than the Wii U, ~5x faster than the Wii U)
32MB eSRAM @ 102GB/s (Not edram)
Orbis
6 x OOE CPU at 1.6 ghz
1.843 Gflops GPU (5-6x more than Wii U; 1,5x more than Durango)
4GB GDDR5 RAM @ 176 GB/s (2x more than Wii U, 15x faster than Wii U; 0.5x less than Durango, 2.5x faster than Durango)
0MB eDram @ 0MB/s (Infinitely less than Wii U; Infinitely less than Durango)
if you were specifically talking about the gpu, its comparable to the radeon hd4650/4670 series (lower clockspeed though and less texture units).I think these cards were released in 2008/2009 so were essentially talking about a 4-5 year old gpu.
not really up to date are we now?
Wii U
3 x OOE CPU at 1.2 ghz
~300-400 Gflops GPU (???)
2GB T1 SRAM @ 12.8 GB/s (???)
32MB eDRAM @ 140 GB/s (???)
1MB sRAM/eDRAM (???)
Durango
6 x OOE CPU at 1.6 ghz
1.243 Gflops GPU (3 - 4x more than Wii U)
8GB DDR3 RAM @ 68GB/s (4x more than the Wii U, ~5x faster than the Wii U)
32MB eSRAM @ 102GB/s (Not edram)
Orbis
6 x OOE CPU at 1.6 ghz
1.843 Gflops GPU (5-6x more than Wii U; 1,5x more than Durango)
4GB GDDR5 RAM @ 176 GB/s (2x more than Wii U, 15x faster than Wii U; 0.5x less than Durango, 2.5x faster than Durango)
0MB eDram @ 0MB/s (Infinitely less than Wii U; Infinitely less than Durango)
if you were specifically talking about the gpu, its comparable to the radeon hd4650/4670 series (lower clockspeed though and less texture units).I think these cards were released in 2008/2009 so were essentially talking about a 4-5 year old gpu.
Tell you me you have one of these! I've been dying to get one myself. Think I saw some on eBay.
http://www.ebay.com/itm/WHOLESALE-H...429?pt=LH_DefaultDomain_0&hash=item4abbd4cd15
not really up to date are we now?
generated?
ever heard of devkits? don't u think those have specs? don't you think there are leaks?? Not everything might be 100% correct but this is what its looking like whether you like it or not
here gpu details off durango for example, but nah you probably dont believe anything.. lmfao @ you getting owned

ever heard of devkits? don't u think those have specs? don't you think there are leaks?? Not everything might be 100% correct but this is what its looking like whether you like it or not
here gpu details off durango for example, but nah you probably dont believe anything.. lmfao @ you getting owned
We will see. Honestly, might buy 720 or PS4 once hacked;-). Had Wii and 360;-). Sony and Microsoft go overkill. Always have but what sells? If they want $400 or more a unit, in this economy, good luck. If they work out and one is hacked, then I get my Zelda, Metroid games AND get my shooters/sports on one of the monsters. Dev kits don't always translate to consumer model specs either;-). We will see;-)

Durango and Orbis specs have been available for quite a while, and considering sony is hold a press conference on feb 20th to more than likely unveil Ps3 Successor, the dev kits just sent out in Jan will prob be pretty close to final specs, I think i will go for the PS4 if all durango info is accurate, either way alot of info is availble on it, Heres some more Durango info to go with table above
ORBIS (PS4 Devkit Specs)
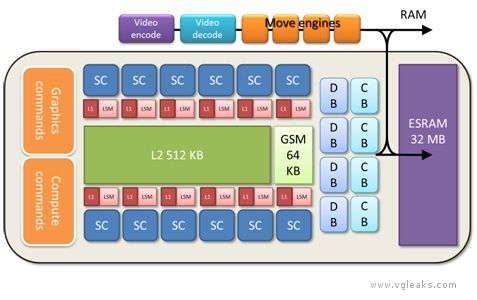
Durango brings the enhanced capabilities of a modern Direct3D 11 GPU to the console space. The Durango GPU is a departure from previous console generations both in raw performance and in structure.
Virtual Addressing
All GPU memory accesses on Durango use virtual addresses, and therefore pass through a translation table before being resolved to physical addresses. This layer of indirection solves the problem of resource memory fragmentation in hardware—a single resource can now occupy several noncontiguous pages of physical memory without penalty.
Virtual addresses can target pages in main RAM or ESRAM, or can be unmapped. Shader reads and writes to unmapped pages return well-defined results, including optional error codes, rather than crashing the GPU. This facility is important for support of tiled resources, which are only partially resident in physical memory
ESRAM
Durango has no video memory (VRAM) in the traditional sense, but the GPU does contain 32 MB of fast embedded SRAM (ESRAM). ESRAM on Durango is free from many of the restrictions that affect EDRAM on Xbox 360. Durango supports the following scenarios:
Local Shared Memory and Global Shared Memory
Each shader core of the Durango GPU contains a 64-KB buffer of local shared memory (LSM). The LSM supplies scratch space for compute shader threadgroups. The LSM is also used implicitly for various purposes. The shader compiler can choose to allocate temporary arrays there, spill data from registers, or cache data that arrives from external memory. The LSM facilitates passing data from one pipeline stage to another (interpolants, patch control points, tessellation factors, stream out, etc.). In some cases, this usage implies that successive pipeline stages are restricted to run on the same SC.
The GPU also contains a single 64-KB buffer of global shared memory (GSM). The GSM contains temporary data referenced by an entire draw call. It is also used implicitly to enforce synchronization barriers, and to properly order accesses to Direct3D 11 append and consume buffers. The GSM is capable of acting as a destination for shader export, so the driver can choose to locate small render targets there for efficiency.
Cache
Durango has a two stage caching system, depicted below.
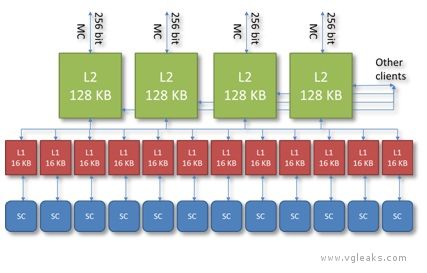
L2 Cache
The GPU contains four separate 8-way L2 caches of 128 KB, each composed of 2048 64-byte cache lines. Each L2 cache owns a certain subset of address space. Texture tiling patterns are chosen to ensure all four caches are equally utilized. The L2 generally acts as a write-back cache—when the GPU modifies data in a cache line, the modifications are not written back to main memory until the cache line is evicted. The L2 cache mediates virtually all memory access across the entire chip, and supplies a variety of types of data, including shader code, constants, textures, vertices, etc., coming either from main RAM or from ESRAM. Shader atomic operations are implemented in the L2 cache.
L1 Cache
Each shader core has a local 64-way L1 cache of 16 KB, composed of 256 64-byte cache lines. The L1 generally acts as a write-through cache—when the SC modifies data in the cache, the modifications are pushed back to L2 without waiting until the cache line is evicted. The L1 cache is used exclusively for data read and written by shaders and is dedicated to coalescing memory requests over the lifetime of a single vector. Even this limited sort of caching is important, since memory accesses tend to be very spatially coherent, both within one thread and across neighboring threads.
The L1 cache guarantees consistent ordering per thread: A write followed by a read from the same address, for example, will give the updated value. The L1 cache does not, however, ensure consistency across threads or across vectors. Such requirements must be enforced explicitly—using barriers in the shader for example. Data is not shared between L1 caches or between SCs except via write-back to the L2 cache.
Unlike some earlier GPUs (including the Xbox 360 GPU), Durango leaves texture and buffer data in native compressed form in the L2 and L1 caches. Compressed data implies a longer fetch pipeline—every L1 cache must now have decoder hardware in it that repeats the same calculation each time the same data is fetched. On the other hand, by keeping data compressed longer, the GPU limits cache footprint and intermediate bandwidth. Following the same principle, sRGB textures are left in gamma space in the cache, and, therefore, have the same footprint as linear textures.
To see how this policy affects cache efficiency, consider an sRGB BC1 texture—perhaps the most commonly encountered texture type in games. BC1 is a 4-bit per texel format; on Durango, this texture occupies 4 bits per texel in the L1 cache. On Xbox 360, the same texture is decompressed and gamma corrected before it reaches the cache, and therefore occupies 8 bytes per texel, or 16 times the Durango footprint. For this reason, the Durango L1 cache behaves like a much larger cache when compared against previous architectures.
Just as SCs can hide fetch latency by switching to other vectors, L1 texture caches on Durango are capable of hiding L2 cache latency by continuing to process fetch instructions after a miss. In other words, when a cache miss is followed by one or more cache hits, the hits can be satisfied during the stall for the miss.
Fetch
Durango supports two types of fetch operation—image fetches and buffer fetches. Image fetches correspond to the Sample method in high-level shader language (HLSL) and require both a texture register and a sampler register. Features such as filtering, wrapping, mipmapping, gamma correction, and block compression require image fetches. Buffer fetches correspond to the Load method in HLSL and require only a texture register, without a sampler register. Examples of buffer fetches are:
Many factors can reduce effective fetch rate. For instance, trilinear filtering, anisotropic filtering, and fetches from volume maps all translate internally to iterations over multiple bilinear fetches. Bilinear filtering of data formats wider than 32-bits per texel also operates at a reduced rate. Floating point formats that have more than three channels operate at half rate. Use of per-pixel gradients causes fetches to operate at quarter rate.
By contrast, fetches from sRGB textures are full rate. Gamma conversion internally uses a modified 7e4 floating-point representation. This format is large enough to be bitwise exact according to the DirectX 10 spec, yet still small enough to fit through a single filtering pipe.
The Durango GPU supports all standard Direct3D 11 DXGI formats, as well as some custom formats.
Compute
Each of the 12 Durango SCs has its own L1 cache, LSM (Local Shared Memory), and scheduler, and four SIMD units. O represents a single thread of the currently executing shader.
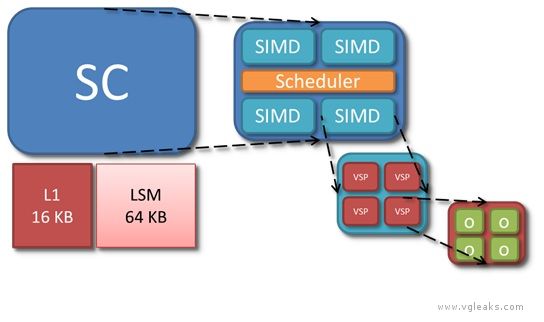
SIMD
Each of the four SIMDs in the shader core is a vector processor in the sense of operating on vectors of threads. A SIMD executes a vector instruction on 64 threads at once in lockstep. Per thread, however, the SIMDs are scalar processors, in the sense of using float operands rather than float4 operands. Because the instruction set is scalar in this sense, shaders no longer waste processing power when they operate on fewer than four components at a time. Analysis of Xbox 360 shaders suggests that of the five available lanes (a float4 operation, co-issued with a float operation), only three are used on average.
The SIMD instruction set is extensive, and supports 32-bit and 64-bit integer and float data types. Operations on wider data types occupy multiple processor pipes, and therefore run at slower rates—for example, 64-bit adds are one-eighth rate, and 64-bit multiplies are 1/16-rate. Transcendental operations, such as square root, reciprocal, exponential, logarithm, sine, and cosine, are non-pipelined and run at quarter rate. These operations should be used sparingly on Durango because they are more expensive relative to arithmetic operations than they are on Xbox 360.
Scheduler
The scheduler of the SC is responsible for loading shader code from memory and controlling execution of the four SIMDs. In addition to managing the SIMDs, the scheduler also executes certain types of instructions on its own. These instructions come from a separate scalar instruction set; they perform an operation per vector rather an operation than per thread. A scalar instruction might be employed, for example, to add two shader constants. In microcode, scalar instructions have names beginning with s_, while vector instructions have names beginning with v_.
The scheduler tracks dependencies within a vector, keeping track of when the next instruction is safe to run. In addition, the scheduler handles dynamic branch logic and loops.
On each clock cycle, the scheduler considers one of the four SIMDs, iterating over them in a round-robin fashion. Most instructions have a four cycle throughput, so each SIMD only needs attention once every four clocks. A SIMD can have up to 10 vectors in flight at any time. The scheduler selects one or more of these 10 candidate vectors to execute an instruction. The scheduler can simultaneously issue multiple instructions of different types—for instance, a vector operation, a scalar operation, a global memory operation, a local memory operation, and a branch operation—but each operation must act on a different vector.
General Purpose Registers
Each SIMD contains 256 vector general purpose registers (VGPRs), and 512 scalar general purpose registers (SGPRs). Both types of GPR store 32-bit data: An SGPR contains a single 32-bit value shared across threads, while a VGPR represents an array of 32-bit values, one per thread within a vector. Each thread can only see its own entry within a VGPR.
GPRs record intermediate results between instructions of the shader. To each newly created vector, the GPU assigns a range of VGPRs and a range of SGPRs—as many as needed by the shader up to a limit of 256 VGPRs and 104 SGPRs. Some GPRs are consumed implicitly by the system—for instance, to hold literal constants, index inputs, barycentric coordinates, or metadata for debugging.
The number of available GPRs can be a limiting factor in the ability of the SIMD to hide latency by switching to other vectors. If all the GPRs for a SIMD are already assigned, then no new vector can begin executing. And then, if all active vectors stall, the SIMD goes idle until one of the stalls ends.
Like most modern GPUs, the Durango GPU uses a unified shader architecture (USA), which means that the same SCs are used interchangeably for all stages of the shader pipeline: vertex, hull, domain, geometry, pixel, and compute. On Durango, GPR usage is also unified; there is no longer any fixed allocation of GPRs to vertex or pixel shading as on Xbox 360.
Constants
The Durango GPU has no dedicated registers to hold shader constants. When a shader references a constant buffer, the compiler decides how these accesses will be implemented. The compiler can specify that constants be preloaded into GPRs. The compiler may fetch constants from memory by using scalar instructions. The compiler may cache constants in the LSM.
A shader constant may be either global (constant over the whole draw call) or indexed (immutable, but varying by thread). Indexed constants must be fetched using vector instructions, and are correspondingly more expensive than global constants. This cost is somewhat analogous to the constant waterfalling penalty from Xbox 360, although the mechanism is different.
Branches
Branch instructions are executed by the scheduler and have the same ideal cost as computation instructions. Just as they do on CPUs, however, branches may incur pipeline stalls while awaiting the result of the instruction which determines the branch direction. Not-taken branches introduce subsequent pipeline bubbles. Taken branches require a read from the instruction cache, which incurs an additional delay. All these potential costs are moot as long as there are enough active vectors to hide the stalls.
Branching is inherently problematic on a SIMD architecture where many threads execute in lockstep, and agreement about the branch direction is not guaranteed. The HLSL compiler can implement branch logic in one of several ways:
The Durango GPU has no fixed function interpolation units. Instead, a dedicated GPU component routes vertex shader output data to the LSM of whichever SC (or SCs) ends up running the pixel shader. This routing mechanism allows pixels to be shaded by a different SC than the one that shaded the associated vertices.
Before pixel shader startup, the GPU automatically populates two registers with interpolation metadata:
This approach to interpolation has the advantage that there is no cost for unused interpolants—the instructions can be omitted or branched over. Conversely, there is no benefit from packing interpolants into float4’s. Nevertheless, for short shaders, interpolation can still significantly impact overall computation load.
Output
Pixel shading output goes through the DB and CB before being written to the depth/stencil and color render targets. Logically, these buffers represent screenspace arrays, with one value per sample. Physically, implementation of these buffers is much more complex, and involves a number of optimizations in hardware.
Both depth and color are stored in compressed formats. The purpose of compression is to save bandwidth, not memory, and, in fact, compressed render targets actually require slightly more memory than their uncompressed analogues. Compressed render targets provide for certain types of fast-path rendering. A clear operation, for example, is much faster in the presence of compression, because the GPU does not need to explicitly write the clear value to every sample. Similarly, for relatively large triangles, MSAA rendering to a compressed color buffer can run at nearly the same rate as non-MSAA rendering.
For performance reasons, it is important to keep depth and color data compressed as much as possible. Some examples of operations which can destroy compression are:
Fill
The GPU contains four physical instances of both the CB and the DB. Each is capable of handling one quad per clock cycle for a total throughput of 16 pixels per clock cycle, or 12.8 Gpixel/sec. The CB is optimized for 64-bit-per-pixel types, so there is no local performance advantage in using smaller color formats, although there may still be a substantial bandwidth savings.
Because alpha-blending requires both a read and a write, it potentially consumes twice the bandwidth of opaque rendering, and for some color formats, it also runs at half rate computationally. Likewise, because depth testing involves a read from the depth buffer, and depth update involves a write to the depth buffer, enabling either state can reduce overall performance.
Depth and Stencil
The depth block occurs near the end of the logical rendering pipeline, after the pixel shader. In the GPU implementation, however, the DB and the CB can interact with rendering both before and after pixel shading, and the pipeline supports several types of optimized early decision pathways. Durango implements both hierarchical Z (Hi-Z) and early Z (and the same for stencil). Using careful driver and hardware logic, certain depth and color operations can be moved before the pixel shader, and in some cases, part or all of the cost of shading and rasterization can be avoided.
Depth and stencil are stored and handled separately by the hardware, even though syntactically they are treated as a unit. A read of depth/stencil is really two distinct operations, as is a write to depth/stencil. The driver implements the mixed format DXGI_FORMAT_D24_UNORM_S8_UINT by using two separate allocations: a 32-bit depth surface (with 8 bits of padding per sample) and an 8-bit stencil surface.
Antialiasing
The Durango GPU supports 2x, 4x, and 8x MSAA levels. It also implements a modified type of MSAA known as compressed AA. Compressed AA decouples two notions of sample:
Under compressed AA, there can be more coverage samples than surface samples. In other words, a triangle may still cover several screenspace locations per pixel, but the GPU does not allocate enough render target space to store a unique depth and color for each location. Hardware logic determines how to combine data from multiple coverage samples. In areas of the screen with extensive subpixel detail, this data reduction process is lossy, but the errors are generally unobjectionable. Compressed AA combines most of the quality benefits of high MSAA levels with the relaxed space requirements of lower MSAA levels.
Source VGleaks.com
Virtual Addressing
All GPU memory accesses on Durango use virtual addresses, and therefore pass through a translation table before being resolved to physical addresses. This layer of indirection solves the problem of resource memory fragmentation in hardware—a single resource can now occupy several noncontiguous pages of physical memory without penalty.
Virtual addresses can target pages in main RAM or ESRAM, or can be unmapped. Shader reads and writes to unmapped pages return well-defined results, including optional error codes, rather than crashing the GPU. This facility is important for support of tiled resources, which are only partially resident in physical memory
ESRAM
Durango has no video memory (VRAM) in the traditional sense, but the GPU does contain 32 MB of fast embedded SRAM (ESRAM). ESRAM on Durango is free from many of the restrictions that affect EDRAM on Xbox 360. Durango supports the following scenarios:
- Texturing from ESRAM
- Rendering to surfaces in main RAM
- Read back from render targets without performing a resolve (in certain cases)
Local Shared Memory and Global Shared Memory
Each shader core of the Durango GPU contains a 64-KB buffer of local shared memory (LSM). The LSM supplies scratch space for compute shader threadgroups. The LSM is also used implicitly for various purposes. The shader compiler can choose to allocate temporary arrays there, spill data from registers, or cache data that arrives from external memory. The LSM facilitates passing data from one pipeline stage to another (interpolants, patch control points, tessellation factors, stream out, etc.). In some cases, this usage implies that successive pipeline stages are restricted to run on the same SC.
The GPU also contains a single 64-KB buffer of global shared memory (GSM). The GSM contains temporary data referenced by an entire draw call. It is also used implicitly to enforce synchronization barriers, and to properly order accesses to Direct3D 11 append and consume buffers. The GSM is capable of acting as a destination for shader export, so the driver can choose to locate small render targets there for efficiency.
Cache
Durango has a two stage caching system, depicted below.
L2 Cache
The GPU contains four separate 8-way L2 caches of 128 KB, each composed of 2048 64-byte cache lines. Each L2 cache owns a certain subset of address space. Texture tiling patterns are chosen to ensure all four caches are equally utilized. The L2 generally acts as a write-back cache—when the GPU modifies data in a cache line, the modifications are not written back to main memory until the cache line is evicted. The L2 cache mediates virtually all memory access across the entire chip, and supplies a variety of types of data, including shader code, constants, textures, vertices, etc., coming either from main RAM or from ESRAM. Shader atomic operations are implemented in the L2 cache.
L1 Cache
Each shader core has a local 64-way L1 cache of 16 KB, composed of 256 64-byte cache lines. The L1 generally acts as a write-through cache—when the SC modifies data in the cache, the modifications are pushed back to L2 without waiting until the cache line is evicted. The L1 cache is used exclusively for data read and written by shaders and is dedicated to coalescing memory requests over the lifetime of a single vector. Even this limited sort of caching is important, since memory accesses tend to be very spatially coherent, both within one thread and across neighboring threads.
The L1 cache guarantees consistent ordering per thread: A write followed by a read from the same address, for example, will give the updated value. The L1 cache does not, however, ensure consistency across threads or across vectors. Such requirements must be enforced explicitly—using barriers in the shader for example. Data is not shared between L1 caches or between SCs except via write-back to the L2 cache.
Unlike some earlier GPUs (including the Xbox 360 GPU), Durango leaves texture and buffer data in native compressed form in the L2 and L1 caches. Compressed data implies a longer fetch pipeline—every L1 cache must now have decoder hardware in it that repeats the same calculation each time the same data is fetched. On the other hand, by keeping data compressed longer, the GPU limits cache footprint and intermediate bandwidth. Following the same principle, sRGB textures are left in gamma space in the cache, and, therefore, have the same footprint as linear textures.
To see how this policy affects cache efficiency, consider an sRGB BC1 texture—perhaps the most commonly encountered texture type in games. BC1 is a 4-bit per texel format; on Durango, this texture occupies 4 bits per texel in the L1 cache. On Xbox 360, the same texture is decompressed and gamma corrected before it reaches the cache, and therefore occupies 8 bytes per texel, or 16 times the Durango footprint. For this reason, the Durango L1 cache behaves like a much larger cache when compared against previous architectures.
Just as SCs can hide fetch latency by switching to other vectors, L1 texture caches on Durango are capable of hiding L2 cache latency by continuing to process fetch instructions after a miss. In other words, when a cache miss is followed by one or more cache hits, the hits can be satisfied during the stall for the miss.
Fetch
Durango supports two types of fetch operation—image fetches and buffer fetches. Image fetches correspond to the Sample method in high-level shader language (HLSL) and require both a texture register and a sampler register. Features such as filtering, wrapping, mipmapping, gamma correction, and block compression require image fetches. Buffer fetches correspond to the Load method in HLSL and require only a texture register, without a sampler register. Examples of buffer fetches are:
- Vertex fetches
- Direct3D 10-style gather4 operations (which fetch a single unfiltered channel from 4 texels, rather than multiple filtered channels from a single texel)
- Fetches from formats that are natively unfilterable, such as integer formats
Many factors can reduce effective fetch rate. For instance, trilinear filtering, anisotropic filtering, and fetches from volume maps all translate internally to iterations over multiple bilinear fetches. Bilinear filtering of data formats wider than 32-bits per texel also operates at a reduced rate. Floating point formats that have more than three channels operate at half rate. Use of per-pixel gradients causes fetches to operate at quarter rate.
By contrast, fetches from sRGB textures are full rate. Gamma conversion internally uses a modified 7e4 floating-point representation. This format is large enough to be bitwise exact according to the DirectX 10 spec, yet still small enough to fit through a single filtering pipe.
The Durango GPU supports all standard Direct3D 11 DXGI formats, as well as some custom formats.
Compute
Each of the 12 Durango SCs has its own L1 cache, LSM (Local Shared Memory), and scheduler, and four SIMD units. O represents a single thread of the currently executing shader.
SIMD
Each of the four SIMDs in the shader core is a vector processor in the sense of operating on vectors of threads. A SIMD executes a vector instruction on 64 threads at once in lockstep. Per thread, however, the SIMDs are scalar processors, in the sense of using float operands rather than float4 operands. Because the instruction set is scalar in this sense, shaders no longer waste processing power when they operate on fewer than four components at a time. Analysis of Xbox 360 shaders suggests that of the five available lanes (a float4 operation, co-issued with a float operation), only three are used on average.
The SIMD instruction set is extensive, and supports 32-bit and 64-bit integer and float data types. Operations on wider data types occupy multiple processor pipes, and therefore run at slower rates—for example, 64-bit adds are one-eighth rate, and 64-bit multiplies are 1/16-rate. Transcendental operations, such as square root, reciprocal, exponential, logarithm, sine, and cosine, are non-pipelined and run at quarter rate. These operations should be used sparingly on Durango because they are more expensive relative to arithmetic operations than they are on Xbox 360.
Scheduler
The scheduler of the SC is responsible for loading shader code from memory and controlling execution of the four SIMDs. In addition to managing the SIMDs, the scheduler also executes certain types of instructions on its own. These instructions come from a separate scalar instruction set; they perform an operation per vector rather an operation than per thread. A scalar instruction might be employed, for example, to add two shader constants. In microcode, scalar instructions have names beginning with s_, while vector instructions have names beginning with v_.
The scheduler tracks dependencies within a vector, keeping track of when the next instruction is safe to run. In addition, the scheduler handles dynamic branch logic and loops.
On each clock cycle, the scheduler considers one of the four SIMDs, iterating over them in a round-robin fashion. Most instructions have a four cycle throughput, so each SIMD only needs attention once every four clocks. A SIMD can have up to 10 vectors in flight at any time. The scheduler selects one or more of these 10 candidate vectors to execute an instruction. The scheduler can simultaneously issue multiple instructions of different types—for instance, a vector operation, a scalar operation, a global memory operation, a local memory operation, and a branch operation—but each operation must act on a different vector.
General Purpose Registers
Each SIMD contains 256 vector general purpose registers (VGPRs), and 512 scalar general purpose registers (SGPRs). Both types of GPR store 32-bit data: An SGPR contains a single 32-bit value shared across threads, while a VGPR represents an array of 32-bit values, one per thread within a vector. Each thread can only see its own entry within a VGPR.
GPRs record intermediate results between instructions of the shader. To each newly created vector, the GPU assigns a range of VGPRs and a range of SGPRs—as many as needed by the shader up to a limit of 256 VGPRs and 104 SGPRs. Some GPRs are consumed implicitly by the system—for instance, to hold literal constants, index inputs, barycentric coordinates, or metadata for debugging.
The number of available GPRs can be a limiting factor in the ability of the SIMD to hide latency by switching to other vectors. If all the GPRs for a SIMD are already assigned, then no new vector can begin executing. And then, if all active vectors stall, the SIMD goes idle until one of the stalls ends.
Like most modern GPUs, the Durango GPU uses a unified shader architecture (USA), which means that the same SCs are used interchangeably for all stages of the shader pipeline: vertex, hull, domain, geometry, pixel, and compute. On Durango, GPR usage is also unified; there is no longer any fixed allocation of GPRs to vertex or pixel shading as on Xbox 360.
Constants
The Durango GPU has no dedicated registers to hold shader constants. When a shader references a constant buffer, the compiler decides how these accesses will be implemented. The compiler can specify that constants be preloaded into GPRs. The compiler may fetch constants from memory by using scalar instructions. The compiler may cache constants in the LSM.
A shader constant may be either global (constant over the whole draw call) or indexed (immutable, but varying by thread). Indexed constants must be fetched using vector instructions, and are correspondingly more expensive than global constants. This cost is somewhat analogous to the constant waterfalling penalty from Xbox 360, although the mechanism is different.
Branches
Branch instructions are executed by the scheduler and have the same ideal cost as computation instructions. Just as they do on CPUs, however, branches may incur pipeline stalls while awaiting the result of the instruction which determines the branch direction. Not-taken branches introduce subsequent pipeline bubbles. Taken branches require a read from the instruction cache, which incurs an additional delay. All these potential costs are moot as long as there are enough active vectors to hide the stalls.
Branching is inherently problematic on a SIMD architecture where many threads execute in lockstep, and agreement about the branch direction is not guaranteed. The HLSL compiler can implement branch logic in one of several ways:
- Predication – Both paths are executed; calculations that should not happen for a particular thread are masked out.
- Predicated jump – If all threads decide the branch in the same way, only the correct path is executed; otherwise, both paths are executed.
- Skip – Both paths are followed, but instructions that are executed by no threads are skipped over at a faster rate.
The Durango GPU has no fixed function interpolation units. Instead, a dedicated GPU component routes vertex shader output data to the LSM of whichever SC (or SCs) ends up running the pixel shader. This routing mechanism allows pixels to be shaded by a different SC than the one that shaded the associated vertices.
Before pixel shader startup, the GPU automatically populates two registers with interpolation metadata:
- One SGPR is a bitfield that contains:
- a pointer to the area of the LSM where vertex shader output was stored
- a description of which pixels in the current vector came from which vertices
- Two VGPRs contain barycentric coordinates for each pixel (the third barycentric coordinate is implicit)
This approach to interpolation has the advantage that there is no cost for unused interpolants—the instructions can be omitted or branched over. Conversely, there is no benefit from packing interpolants into float4’s. Nevertheless, for short shaders, interpolation can still significantly impact overall computation load.
Output
Pixel shading output goes through the DB and CB before being written to the depth/stencil and color render targets. Logically, these buffers represent screenspace arrays, with one value per sample. Physically, implementation of these buffers is much more complex, and involves a number of optimizations in hardware.
Both depth and color are stored in compressed formats. The purpose of compression is to save bandwidth, not memory, and, in fact, compressed render targets actually require slightly more memory than their uncompressed analogues. Compressed render targets provide for certain types of fast-path rendering. A clear operation, for example, is much faster in the presence of compression, because the GPU does not need to explicitly write the clear value to every sample. Similarly, for relatively large triangles, MSAA rendering to a compressed color buffer can run at nearly the same rate as non-MSAA rendering.
For performance reasons, it is important to keep depth and color data compressed as much as possible. Some examples of operations which can destroy compression are:
- Rendering highly tessellated geometry
- Heavy use of alpha-to-mask (sometimes called alpha-to-coverage)
- Writing to depth or stencil from a pixel shader
- Running the pixel shader per-sample (using the SV_SampleIndex semantic)
- Sourcing the depth or color buffer as a texture in-place and then resuming use as a render target
Fill
The GPU contains four physical instances of both the CB and the DB. Each is capable of handling one quad per clock cycle for a total throughput of 16 pixels per clock cycle, or 12.8 Gpixel/sec. The CB is optimized for 64-bit-per-pixel types, so there is no local performance advantage in using smaller color formats, although there may still be a substantial bandwidth savings.
Because alpha-blending requires both a read and a write, it potentially consumes twice the bandwidth of opaque rendering, and for some color formats, it also runs at half rate computationally. Likewise, because depth testing involves a read from the depth buffer, and depth update involves a write to the depth buffer, enabling either state can reduce overall performance.
Depth and Stencil
The depth block occurs near the end of the logical rendering pipeline, after the pixel shader. In the GPU implementation, however, the DB and the CB can interact with rendering both before and after pixel shading, and the pipeline supports several types of optimized early decision pathways. Durango implements both hierarchical Z (Hi-Z) and early Z (and the same for stencil). Using careful driver and hardware logic, certain depth and color operations can be moved before the pixel shader, and in some cases, part or all of the cost of shading and rasterization can be avoided.
Depth and stencil are stored and handled separately by the hardware, even though syntactically they are treated as a unit. A read of depth/stencil is really two distinct operations, as is a write to depth/stencil. The driver implements the mixed format DXGI_FORMAT_D24_UNORM_S8_UINT by using two separate allocations: a 32-bit depth surface (with 8 bits of padding per sample) and an 8-bit stencil surface.
Antialiasing
The Durango GPU supports 2x, 4x, and 8x MSAA levels. It also implements a modified type of MSAA known as compressed AA. Compressed AA decouples two notions of sample:
- Coverage sample–One of several screenspace positions generated by rasterization of one pixel
- Surface sample– One of several entries representing a single pixel in a color or depth/stencil surface
Under compressed AA, there can be more coverage samples than surface samples. In other words, a triangle may still cover several screenspace locations per pixel, but the GPU does not allocate enough render target space to store a unique depth and color for each location. Hardware logic determines how to combine data from multiple coverage samples. In areas of the screen with extensive subpixel detail, this data reduction process is lossy, but the errors are generally unobjectionable. Compressed AA combines most of the quality benefits of high MSAA levels with the relaxed space requirements of lower MSAA levels.
Source VGleaks.com
ORBIS (PS4 Devkit Specs)
Currently, there are 3 types of devkits:
1) R10 boards with special BIOS, running in generic PC’s
2) “Initial 1″ — Early devkit
R10 Board (with special BIOS) assemble in a Generic PC
DVKT-KS000K (“Initial 1″)
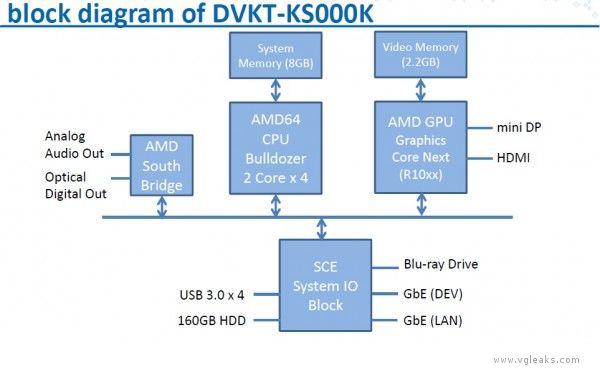
DVKT-KS000K
SoC Based Devkit
EXPECTED SPECS OVERVIEW IN RETAIL
CPU:
GPU:
Memory:
Storage:
High speed Blu-ray drive
Internal Mass Storage:
Networking:
Peripherals:
Extra:
Each CU contains dedicated:
About 14 + 4 balance:
Dual Shader Engines:
18 Texture units:
8 Render backends:

1) R10 boards with special BIOS, running in generic PC’s
2) “Initial 1″ — Early devkit
- model number: DVKT-KS000K
- SCE-provided PC equipped with R10XX board
- Runs Orbis OS
- Available July 2012
- Available January 2013
R10 Board (with special BIOS) assemble in a Generic PC
- Requires Windows 7 64 bit edition
- Recommend
- Sandy Bridge (Intel) or Bulldozer (AMD)
- Minimum 8 GB RAM (system memory)
- 650 Watt PSU
- VS2010 SP1
- DWM (Desktop Windows Manager) must be turned off
- Application will use Windows services for everything except GPU interface
- SCE will provide “Gnm”, a custom GPU interface
DVKT-KS000K (“Initial 1″)
- Runs Orbis OS
- CPU: Bulldozer 8-core, 1.6 Ghz
- Graphics Card: R10 with special BIOS
- RAM: 8 GB (system memory)
- BD Drive
- HDD: 2.5 ” 160 GB
- Network Controller
- Custom South Bridge allows access to controller prototypes
DVKT-KS000K
SoC Based Devkit
- Available January 2013
- CPU: 8-core Jaguar
- GPU: Liverpool GPU
- RAM: unified 8 GB for devkit (4 GB for the retail console)
- Subsystem: HDD, Network Controller, BD Drive, Bluetooth Controller, WLAN and HDMI (up to 1980×1080@3D)
- Analog Outputs: Audio, Composite Video
- Connection to Host: USB 3.0 (targeting over 200 MB/s),
- ORBIS Dualshock
- Dual Camera
EXPECTED SPECS OVERVIEW IN RETAIL
- Custom implementation of AMD Fusion APU Arquitecture (Accelerated Processing Unit)
- Provides good performance with low power consumption
- Integrated CPU and GPU
- Considerably bigger and more powerful than AMD’s other APUs
CPU:
- Orbis contains eight Jaguar cores at 1.6 Ghz, arranged as two “clusters”
- Each cluster contains 4 cores and a shared 2MB L2 cache
- 256-bit SIMD operations, 128-bit SIMD ALU
- SSE up to SSE4, as well as Advanced Vector Extensions (AVX)
- One hardware thread per core
- Decodes, executes and retires at up to two intructions/cycle
- Out of order execution
- Per-core dedicated L1-I and L1-D cache (32Kb each)
- Two pipes per core yield 12,8 GFlops performance
- 102.4 GFlops for system
GPU:
- GPU is based on AMD’s “R10XX” (Southern Islands) architecture
- DirectX 11.1+ feature set
- Liverpool is an enhanced version of the architecture
- 18 Compute Units (CUs)
- Hardware balanced at 14 CUs
- Shared 512 KB of read/write L2 cache
- 800 Mhz
- 1.843 Tflops, 922 GigaOps/s
- Dual shader engines
- 18 texture units
- 8 Render backends
Memory:
- 4 GB unified system memory, 176 GB/s
- 3.5 available to games (estimate)
Storage:
High speed Blu-ray drive
- Single layer (25 GB) or dual layer (50 GB) discs
- Partial constant angular velocity (PCAV)
- Outer half of disc 6x (27 MB/s)
- Inner half varies, 3.3x to 6x
Internal Mass Storage:
- One SKU at launch: 500 GB HDD
- There may also be a Flash drive SKU in the future
Networking:
- 1 Gb/s Ethernet, 802.11b/g/n WIFI, and Bluetooth
Peripherals:
- Evolved Dualshock controller
- Dual Camera
- Move controller
Extra:
- Audio Processor (ACP)
- Video encode and decode (VCE/UVD) units
- Display ScanOut Engine (DCE)
- Zlib Decompression Hardware
Each CU contains dedicated:
- ALU (32 64-bit operations per cycle)
- Texture Unit
- L1 data cache
- Local data share (LDS)
About 14 + 4 balance:
- 4 additional CUs (410 Gflops) “extra” ALU as resource for compute
- Minor boost if used for rendering
Dual Shader Engines:
- 1.6 billion triangles/s, 1.6 billion vertices/s
18 Texture units:
- 56 billion bilinear texture reads/s
- Can utilize full memory bandwith
8 Render backends:
- 32 color ops/cycle
- 128 depth ops/cycle
- Can utilize full memory bandwith

- Joined
- Apr 29, 2011
- Messages
- 31,284
- Trophies
- 2
- Age
- 38
- Location
- Dr. Wahwee's castle
- XP
- 18,969
- Country

The hardware doesn't make the console a success. History has proved this numerous times. Focus too much on power, your console is SOL.
DS vs PSP = DS wins
3DS vs PS Vita = 3DS wins
Wii vs PS3 and Xbox 360 = Wii wins
PSX vs N64 = PSX wins
PS2 vs Gamecube and Xbox = PS2 wins
Snes vs Genesis = Snes wins
GBA vs WonderSwan Color and Neo Geo Pocket = GBA wins
See the pattern? More powerful hardware doesn't make a console a success. Same with games with flashy graphics. A game can be beautifully rendered and still suck balls, you know, Final Fantasy XIII, Lair to name a few. You know why Nintendo doesn't focus on raw power.
DS vs PSP = DS wins
3DS vs PS Vita = 3DS wins
Wii vs PS3 and Xbox 360 = Wii wins
PSX vs N64 = PSX wins
PS2 vs Gamecube and Xbox = PS2 wins
Snes vs Genesis = Snes wins
GBA vs WonderSwan Color and Neo Geo Pocket = GBA wins
See the pattern? More powerful hardware doesn't make a console a success. Same with games with flashy graphics. A game can be beautifully rendered and still suck balls, you know, Final Fantasy XIII, Lair to name a few. You know why Nintendo doesn't focus on raw power.

For f**k's sake, the_randomizer, STOP hijacking threads.

I don't know how you can say this. I understand the Wii sold like hot cakes in it's first few years, but since then the 360 has led monthly sales.Wii vs PS3 and Xbox 360 = Wii wins
When it comes to volume of games sold, the Wii isn't even in the same league as PS3 and 360.
Also when it comes to developer support, the Wii lost most developer interest a few years ago. It's mostly shovelware.
The AAA developers have focused on the 360 and PS3, spending multimillions in development and getting very good return on their investment.
If you asked the developers why they didn't bother with Wii, it's due to inferior hardware. They would have needed to design a completely different version of their game because the Wii couldn't run their game engine, and had they done that, they wouldn't have sold as well as the 360/PS3 versions.
Only now are some of those of those titles ported to Wii-u (Batman, Assassins Creed).
Don't get me wrong, I love the Wii for it's first party titles. The Wii broke ground with it's motion control. It also captured a market of casual gamers that weren't otherwise interested in buying consoles.
The problem is, that market let their Wii's collect dust and didn't buy new titles... hence developers losing interest.
Listen, I agree with you that the very best hardware isn't needed to move games, I just disagree with your list.
And are you trying to say that the Genesis was more powerful than Super Nintendo?
D
Deleted_171835
Guest
http://gbatemp.net/threads/wii-u-latte-gpu-details-revealed.342461/unread
Now how about you guys move the actual discussion to the drama-free no bullshit thread.
Now how about you guys move the actual discussion to the drama-free no bullshit thread.
- Joined
- Apr 29, 2011
- Messages
- 31,284
- Trophies
- 2
- Age
- 38
- Location
- Dr. Wahwee's castle
- XP
- 18,969
- Country
I don't know how you can say this. I understand the Wii sold like hot cakes in it's first few years, but since then the 360 has led monthly sales.
When it comes to volume of games sold, the Wii isn't even in the same league as PS3 and 360.
Also when it comes to developer support, the Wii lost most developer interest a few years ago. It's mostly shovelware.
The AAA developers have focused on the 360 and PS3, spending multimillions in development and getting very good return on their investment.
If you asked the developers why they didn't bother with Wii, it's due to inferior hardware. They would have needed to design a completely different version of their game because the Wii couldn't run their game engine, and had they done that, they wouldn't have sold as well as the 360/PS3 versions.
Only now are some of those of those titles ported to Wii-u (Batman, Assassins Creed).
Don't get me wrong, I love the Wii for it's first party titles. The Wii broke ground with it's motion control. It also captured a market of casual gamers that weren't otherwise interested in buying consoles.
The problem is, that market let their Wii's collect dust and didn't buy new titles... hence developers losing interest.
Listen, I agree with you that the very best hardware isn't needed to move games, I just disagree with your list.
And are you trying to say that the Genesis was more powerful than Super Nintendo?
The CPU was faster than the Snes, but the Snes had a better APU (audio) and PPU (graphics) than the Genesis.
- Joined
- Apr 29, 2011
- Messages
- 31,284
- Trophies
- 2
- Age
- 38
- Location
- Dr. Wahwee's castle
- XP
- 18,969
- Country
Fair enough.
But yeah, I grew up on the Snes, ultimately getting me hooked on Nintendo since 1993
- Joined
- Nov 15, 2011
- Messages
- 5,210
- Trophies
- 0
- Age
- 40
- Location
- Deep in GBAtemp addiction
- Website
- gbadev.googlecode.com
- XP
- 1,709
- Country
Not quite the GPU or even the main processor but this is the first thing I found in GoogleAnyone have a die picture of the snes gpu?
http://byuu.org/articles/emulation/snes-coprocessors
I know their just coprocessors but MAN things were a lot simpler back then.


- Joined
- Apr 29, 2011
- Messages
- 31,284
- Trophies
- 2
- Age
- 38
- Location
- Dr. Wahwee's castle
- XP
- 18,969
- Country
Actually, the Snes CPU was 3.58 MHz, but the Super FX chip was 21 MHz.
PSX was NOT 3.2 GHZ, with "9 Cores"; show proof of that. Modern processors would be that speed.Actually, the Snes CPU was 3.58 MHz, but the Super FX chip was 21 MHz.
Similar threads
- Replies
- 3
- Views
- 768
- Replies
- 23
- Views
- 779
- Replies
- 4
- Views
- 573
- Replies
- 1
- Views
- 344
Site & Scene News
New Hot Discussed
-
-
58K views
Nintendo Switch firmware 18.0.0 has been released
It's the first Nintendo Switch firmware update of 2024. Made available as of today is system software version 18.0.0, marking a new milestone. According to the patch... -
28K views
GitLab has taken down the Suyu Nintendo Switch emulator
Emulator takedowns continue. Not long after its first release, Suyu emulator has been removed from GitLab via a DMCA takedown. Suyu was a Nintendo Switch emulator... -
20K views
Atmosphere CFW for Switch updated to pre-release version 1.7.0, adds support for firmware 18.0.0
After a couple days of Nintendo releasing their 18.0.0 firmware update, @SciresM releases a brand new update to his Atmosphere NX custom firmware for the Nintendo...by ShadowOne333 94 -
18K views
Wii U and 3DS online services shutting down today, but Pretendo is here to save the day
Today, April 8th, 2024, at 4PM PT, marks the day in which Nintendo permanently ends support for both the 3DS and the Wii U online services, which include co-op play...by ShadowOne333 176 -
16K views
Denuvo unveils new technology "TraceMark" aimed to watermark and easily trace leaked games
Denuvo by Irdeto has unveiled at GDC (Game Developers Conference) this past March 18th their brand new anti-piracy technology named "TraceMark", specifically tailored...by ShadowOne333 101 -
15K views
GBAtemp Exclusive Introducing tempBOT AI - your new virtual GBAtemp companion and aide (April Fools)
Hello, GBAtemp members! After a prolonged absence, I am delighted to announce my return and upgraded form to you today... Introducing tempBOT AI 🤖 As the embodiment... -
12K views
Pokemon fangame hosting website "Relic Castle" taken down by The Pokemon Company
Yet another casualty goes down in the never-ending battle of copyright enforcement, and this time, it hit a big website which was the host for many fangames based and...by ShadowOne333 65 -
11K views
MisterFPGA has been updated to include an official release for its Nintendo 64 core
The highly popular and accurate FPGA hardware, MisterFGPA, has received today a brand new update with a long-awaited feature, or rather, a new core for hardcore...by ShadowOne333 51 -
11K views
Apple is being sued for antitrust violations by the Department of Justice of the US
The 2nd biggest technology company in the world, Apple, is being sued by none other than the Department of Justice of the United States, filed for antitrust...by ShadowOne333 80 -
10K views
The first retro emulator hits Apple's App Store, but you should probably avoid it
With Apple having recently updated their guidelines for the App Store, iOS users have been left to speculate on specific wording and whether retro emulators as we...
-
-
-
223 replies
Nintendo Switch firmware 18.0.0 has been released
It's the first Nintendo Switch firmware update of 2024. Made available as of today is system software version 18.0.0, marking a new milestone. According to the patch...by Chary -
176 replies
Wii U and 3DS online services shutting down today, but Pretendo is here to save the day
Today, April 8th, 2024, at 4PM PT, marks the day in which Nintendo permanently ends support for both the 3DS and the Wii U online services, which include co-op play...by ShadowOne333 -
169 replies
GBAtemp Exclusive Introducing tempBOT AI - your new virtual GBAtemp companion and aide (April Fools)
Hello, GBAtemp members! After a prolonged absence, I am delighted to announce my return and upgraded form to you today... Introducing tempBOT AI 🤖 As the embodiment...by tempBOT -
146 replies
GitLab has taken down the Suyu Nintendo Switch emulator
Emulator takedowns continue. Not long after its first release, Suyu emulator has been removed from GitLab via a DMCA takedown. Suyu was a Nintendo Switch emulator...by Chary -
101 replies
Denuvo unveils new technology "TraceMark" aimed to watermark and easily trace leaked games
Denuvo by Irdeto has unveiled at GDC (Game Developers Conference) this past March 18th their brand new anti-piracy technology named "TraceMark", specifically tailored...by ShadowOne333 -
96 replies
The first retro emulator hits Apple's App Store, but you should probably avoid it
With Apple having recently updated their guidelines for the App Store, iOS users have been left to speculate on specific wording and whether retro emulators as we...by Scarlet -
94 replies
Atmosphere CFW for Switch updated to pre-release version 1.7.0, adds support for firmware 18.0.0
After a couple days of Nintendo releasing their 18.0.0 firmware update, @SciresM releases a brand new update to his Atmosphere NX custom firmware for the Nintendo...by ShadowOne333 -
80 replies
Apple is being sued for antitrust violations by the Department of Justice of the US
The 2nd biggest technology company in the world, Apple, is being sued by none other than the Department of Justice of the United States, filed for antitrust...by ShadowOne333 -
68 replies
Delta emulator now available on the App Store for iOS
The time has finally come, and after many, many years (if not decades) of Apple users having to side load emulator apps into their iOS devices through unofficial...by ShadowOne333 -
65 replies
Pokemon fangame hosting website "Relic Castle" taken down by The Pokemon Company
Yet another casualty goes down in the never-ending battle of copyright enforcement, and this time, it hit a big website which was the host for many fangames based and...by ShadowOne333
-
Popular threads in this forum
General chit-chat
- No one is chatting at the moment.
-
-
-
-
-
-
-
-
 @
Xdqwerty:
@Purple_Heart, then I will be actually older than him for a bit (ik thats not how ages work btw)
@
Xdqwerty:
@Purple_Heart, then I will be actually older than him for a bit (ik thats not how ages work btw) -
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-
-

